

Obsttorte
-
Posts
6522 -
Joined
-
Last visited
-
Days Won
112
Posts posted by Obsttorte
-
-
The DarkRadiant scripts are written with python iirc. So if you have some good ideas of what could be useful to mappers, this might be worth a start. (I am not sure whether there is any thread with script wishes, though).
Also, programmers are always welcome. If you are experienced in python you will probably be able to dig yourself into C++. The bugtracker is full of stuff that needs fixing.
")
-
 1
1
-
-
Regarding the script function I would assume that having one function only that returns -1 if the item is not stackable as you proposed makes the most sense.
I never thought of having different custom guis for different inventory items. I am not even sure what this could be useful for. I for one would be way to lazy to write several guis
 But in that case overwriting the existing gui file is indeed not going to work well.
But in that case overwriting the existing gui file is indeed not going to work well.
-
5 hours ago, Geep said:
And maybe put in a feature request to the bugtracker to add a getCurInvItemCount() function, for the future.
I can add this script function either way as I am messing around with the code currently. But maybe the workaround makes this unnecessary.
-
1
-
-
Ah, now I see what you mean. My approach always was to override existing files, so I never came to the idea of doing it like that. But if the game allows items to tell the engine to use a different gui, then it should either provide the informations independent from the gui used or an alternative access (like a script function).
From what I've seen in the code it seems indeed to be the case that the desired behaviour is not done by the sdk, probably as said one can't know which gui variables exist and which not. The question is whether under that circumstances it is the best way to use the stackable entity type in combination with a custom gui (the fact it is stackable is more an abstract concept, the player doesn't really have several instances of an item)?
Maybe I can figure out something.
-
1
-
-
The amount of the currently selected, stackable inventory item is stored in the gui variable "gui::Inventory_ItemCount". You don't have to set this manually, the sdk handles this for you. The only thing a scriptobject for such an item has to do is to perform the desired action on use and reduce the count by one.
I would suggest that you take a look at the scriptobject of stackable items and the hud gui to see how it is setup.
-
4 hours ago, Dragofer said:
It started as a request for an arm raising animation. Meanwhile it's become a custom test build.
@Obsttorte do you want it to be moved to the Dark Mod or Editor Guild subforum?
The Dark Mod subforum is probably more fitting, as it isn't related to TDM editing. Thanks.
-
@Oktokolo There is no point in "anticipating behaviour" if it is completely random and leads to players quicksaving before approaching ai, just to quickload again on failure and repeat the exact same pattern that works this time just because a different random animation got played. And of course you can try to knockout any ai before it detects you, but that more or less neglects the whole purpose of pickpocketing.
The player needs to have a chance to anticipate, some information that helps him to decide upon. When a guard is going to relight a light, it will significantly move apart a typical route, and the light won't shine immediately, but an animation is played accompanied by spark particles and sound. If it is an electric light you can see the ai approaching a switch. So there it is clear what will happen and so you can anticipate.
A change of direction is normally within the shapes of the surrounding level geometry, so it makes sense and can be expected. A stationary guard that sometimes turns around will (if properly setup) do so often enough that the player is aware of that behaviour before getting close enough, so he can adjust his tactic.
The issue here is a completely different one and, what is also important, not intented! This happens only with one animation for a specific class of ai. So it can easely happen that even a long time player doesn't even notice this behaviour. How do you expect someone to anticipate that under such circumstances?!
5 hours ago, Oktokolo said:3. Fix the animation.
This isn't a bug in the engine. It is acting like intended. The issue is with an animation, that didn't take player expectaions into account.The problem is that in the future every modeler making an animation would have to made aware of this, which is not likely to happen. So on the long run we would be going to run into this issue over and over again.
-
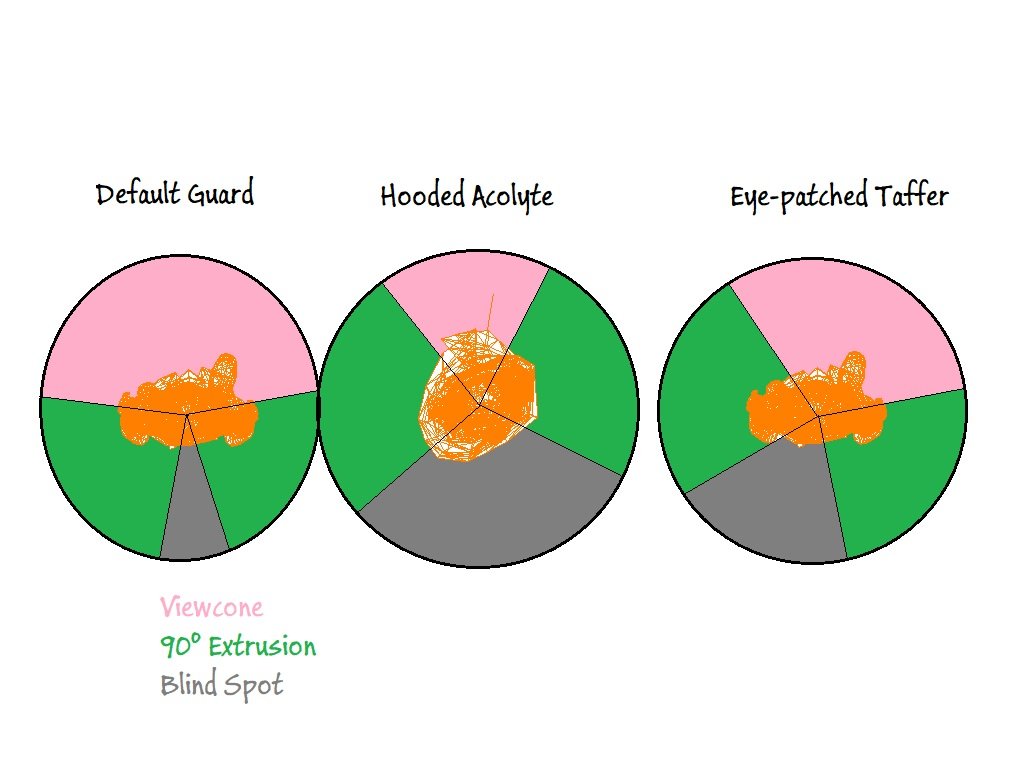
I've filed a bugtracker for the issue. The view angle depending blind spot works basically. The only thing I couldn't get to work is to take the orientation into account, as with the eye-patch carrying ai.
The issue is that the unrotated fov isn't always pointing forward for all ai (whoever thought that would be clever
 ). It does so for humans, but it points downwards for spiders for example. I've tried to figure out a way to get the required info from the data available, but thus far no luck. I am not sure whether it is a real issue though, as the only usecase is the eye-patch gui. If those have a symmetrical blind spot the world would probably not stop turning.
). It does so for humans, but it points downwards for spiders for example. I've tried to figure out a way to get the required info from the data available, but thus far no luck. I am not sure whether it is a real issue though, as the only usecase is the eye-patch gui. If those have a symmetrical blind spot the world would probably not stop turning.
The 30 degree cone one get by standard ai is actually big enough. It easely allows you to get close up to 40 doom units to the ai, if not closer (blackjacking distance is 56, pickpocketing is 40).
-
2
-
 1
1
-
-
Just tested myself, same build, same mission. No problems on my end.
-
Maybe you should hammers this time. We all know what those dudes do secretely in the confessional.
-
1 hour ago, Springheel said:
What method do you plan to use to block their vision? Humanoid AI with special cone values always see less than the default, not more, so if it's an extra spawnarg, a default block value should work in those cases. There might be special AI, like spiders or willowisps, that see more than 180 degrees though.
My initial idea was that, if I assume that ai can turn their head by 90° in both directions, the area in which the ai can never see is what is left if you extrude the forward pointing viewcone by 90° in both directions and take the complement. The problem is that the default horizontal fov is 150°, so this would lead to a very narrow cone in the back (doubling the angle or similar might work better). (#) Such an approach would cause ai with 180°+ fov to not have a blind spot (although I just checked and spiders, zombies, fire elementals et al. have the same viewcone as human ai).
(#) If one assume that even a non-restricted ai cannot see what's behind it, then restricted ai might not need extra threatment.
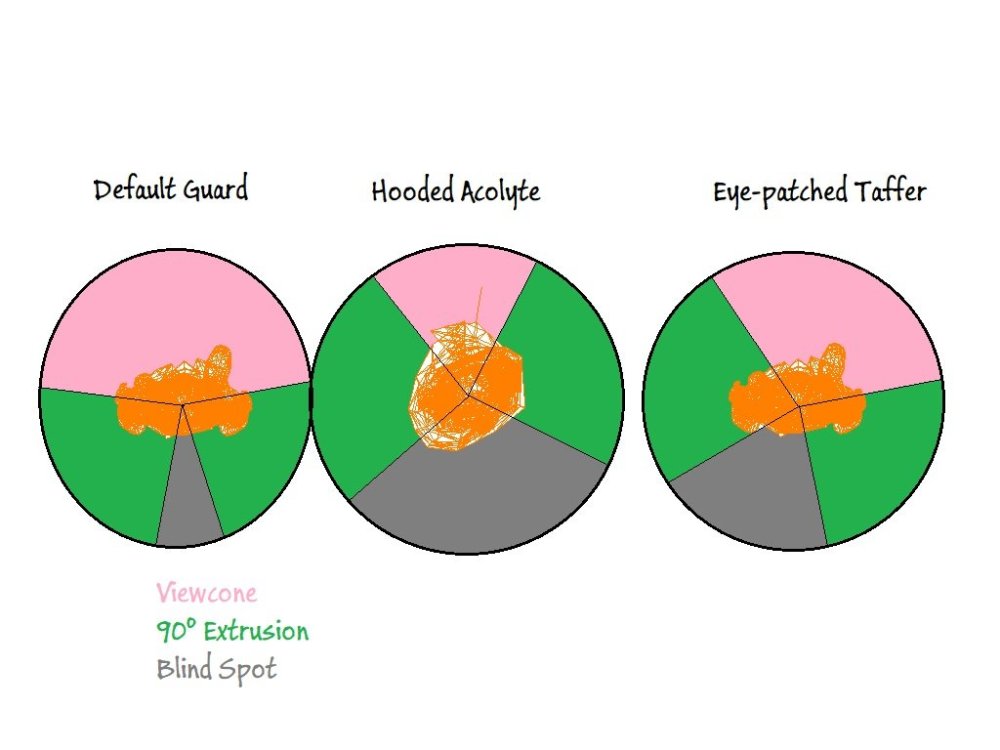
During this I have only taken human-like ai into account thus far, to be honest, as those are the ones with the respective head animations that cause the issue. Using a dedicated spawnarg to specify the blocked off area might also be a good approach here, as it would also be easy to modify the defs accordingly as only the base definitions need change. But from what I've seen thus far I am not sure this is necessary.
-
47 minutes ago, HMart said:
And guys don't take me wrong, TDM being a Thief homage, I don't think should go crazy on physics, I just think that with a better physics engine, some doors would open to make some cool physics based stuff, in or outside the TDM/Thief lore.
Well, to be honest we had discussions about physic based puzzles since I am a member of this forum (and most likely earlier on), but the restrictions of the physics engine always made such things a cumbersome undertaking. So while we may not need the ability to mess around with houndreds of moveables at the same time, a more reliably system is always welcome. And as @stgatilovmentioned, especially the lack of proper transitivity handling is really worth a look.
Personally I think puzzles (and therefore some useful physics) fit the Thief games pretty well, as they are pretty close to action adventure games. I mean, if you would have asked someone back in 1998 what game is closest to Thief, Tomb Raider would probably be on the table
")
-
2
-
-
So, blocking the ai's vision backwards does do the trick. The question is what we should define as behind. We can either use a constant angle, which makes the implementation simple (like in finished
) or we could make it depending on the ai's vision, which would need a bit more love.
Some ai' have there horizontal vision modified, either because they wear a helmet or a cape or because they have an eyepatch. It may not be necessary to take these things into account as the play may not end up within the viewcones of those special cases anyways. Thoughts?
-
2 hours ago, stgatilov said:
What exactly you don't like in how TDM behaves in this scenario?
Probably the performance drop?!
-
2
-
-
1 hour ago, Oktokolo said:
But gaming against a clock was never fun for me.
That point is valid if the clock is really working against you, like if you have to do something within a certain amount of time or else game over. If the amount of time it takes you to get to a certain point decides on how the story evolves from there, then this could actually add a nice touch to a mission, if executed properly.
Gaming is always about making decisions, so why shouldn't the amount of time you invest into something be part of the deal.
-
Investigating further on that issue turned out that the self-occlusion (or its absence) isn't the issue here. The actual problem comes from the animation. The ai is leaning forward while at the same time slightly moving its torso to one side. If you replicate this irl you will notice that you are indeed able to see behind you in that case.
I see two possible solutions:
- Avoid any animations like that as idle animations
- Introduce an additional check to explicitely exclude the possibility of the ai to see anything behind itself (behind in respective to its bodies orientation).
I favor the second one as it means less work for anyone working with animations. I mean, nobody expect that to happen anyway.
-
Some things I've noticed in that Shadwen video:
- The dampening of the ragdolls is much stronger than in TDM, meaning they are coming to an rest earlier on
- The objects colliding with the ai clips into the latter
- it doesn't really look as if the ragdoll physic gets updated each frame, but that may only appear so due to the framerate of the video
All of this could however potentially increase performance. In TDM, the code tries to avoid clipping as much as possible, updates the physic of each actor every frame and puts object only to a rest once they are already almost non moving.
The video in the twitter post is a different matter, though. Although I am not sure this would applyable in a TDM trap usecase scenario. I mean there aren't that many ai in the video posted by @AluminumHaste, so the performance impact is most likely not the amount of ai.
-
I've just taken a look at the code and it is indeed the case that the ai is excluded during the visibility check, meaning that the ai's body does not occlude view. This is most likely to avoid parts of the ai model to interfer with the trace. The same is done with weapons collision testing for example to avoid weapons to collide with themself.
I will see what happens if I disable this and if it causes issues (what is to be expected) will try to implement a workaround.
-
1
-
-
- Popular Post
- Popular Post
Update (source commit #10105):
- The mage bug as reported by @Frost_Salamanderis fixed
- The code now takes the body orientation instead of the head orientation as fundament for the knockout test to prevent random anim based headturns from failing a knockout attempt. (As suggested by @Dragofer)
For those without svn access I have update the files on the ftp server.
-
5
-
I second that.
-
That was the plan to begin with.
-
Nice. I was so free to setup everything for it to be used as a LOD model in TDM. Two notes, though:
- The lod distance values are set erratic. They probably need tweaking. But this is something mission authors should do anyway.
- The models don't seem to have a dedicated shadow mesh. That could make them unneccessarely performance houngry. Someone with model expertise would have to take a look at this.
https://www.mediafire.com/file/nwdnwtriio5d0co/tdm_statue_sealandbear.pk4/file
-
I am not a fan of having several rulesets. Especially new players would have no idea what the difference is and mission authors would have to take both sets into consideration.
-
1
-
-
@IdealWell, that's definetely an issue. I never noticed this as in a case as demonstrated by you in that videos I wouldn't have gave the ai enough time to react like that. His back is just soooo inviting for a knockout
 3 hours ago, Springheel said:
3 hours ago, Springheel said:One possible approach is to see if AI vision can be affected by frame commands in animations.
Frame commands can be used to execute routines in the source code, as done by the blackjack attack animation for example. The question is whether there is an already existing set of code we can utilize or whether something new has to be implemented (and if so, what, of course).
What I wonder is whether it is really necessary to have such a wide vertical view angle. It seems to me that this is partly a reason for the ai reaction, as he leans forward. Another thing to investigate is whether the ai's body is taken into consideration when checking the visibility of the player. I am not sure whether this is the case here.
-
2
-
Things that could be improved
in The Dark Mod
Posted
That's funny (and a bug, of course). I may take a look.
No, the ai does not have to know the direction or where north is, nor do they have a concept of front. Both issues are not connected in any way. (My comment wasn't aimed at any of that, it was about how to handly the eye-patch special case).
In regards to vision, there is a direction of the head model that is defined as forward, and the code checks whether the player is within a cone centered around that direction (in addition to some other conditions).
Pathfinding is done via an abstraction of the level geometry. It's basically a table that contains information on what the shortest route between different areas is, and which areas need to be traversed in what order to get from one point to another. What appears to be a movement like in real life is basically a sliding into a specific direction, that the model was previously turned towards, and an animation played (a bit like when you move a chess figure, only animated).