Search the Community
Searched results for '/tags/forums/language strings/' or tags 'forums/language strings/q=/tags/forums/language strings/&'.
-
This is how i18n typically works in code: Developers write the strings in English (or their native language), but mark all the strings with a function/macro which identifies them for translation. In C++ this might be _("blah") or tr("blah") — something which is short and easy to write. A tool (which may be integrated into the build system), extracts all the strings marked for translation into a big list of translatable strings. This list is then provided to the translators, who do not need to be developers or compile the code themselves. They just create a translation for each listed string and send back a file in the appropriate format (which may or may not be created with the help of translation tools, perhaps with a GUI). At runtime, the code looks up each translatable string, finds the corresponding translated string in the chosen language, and shows the translated version. At no point do developers (who in this case would be mission authors) have to mess around with manually choosing string IDs. All they do is use the appropriate function/macro/syntax to mark particular strings as translatable. String IDs may be used internally but are completely invisible to developers. I suggest that any system that involves instructions like "search the list of known strings for a similar string" or "manually choose a string ID between 20000 and 89999 and then write it as #str_23456" are over-complicated, un-ergonomic and doomed to be largely ignored by mappers.
-
That is one reason. That is 2 more reasons. You'd like a script that, if you had to run it again, would "do the right thing". Unfortunately, that right thing is very hard to program, and needs IMHO to be both bidirectional and with a better method of string version control, to support both the FM author's updates and potentially multiple translators. Yes, another reason. Currently, it is my understanding that updating an FM (from the non-converted copy) and running the conversion script again causes mis-alignment of newly-generated #str values and previous .lang #str values. Another important cause of "nobody is making these language packs" is that Dark Radiant at best tolerates converted FMs. It offers no special translation support, as expressed in this code comment: "...we don't have any support for parsing the mod-specific translation data...." [from DR's DifficultySettingsManager.cpp]. That's where we are now. So officially give up on FM Western translations? Or improve the #str system to make it work for everyone? Or invent a new system? A new system. What would that look like to the FM author? To a non-author translator
-
Well if you go to the mission downloader again, it will show a new update for the mission, which is the translation pack. If I select Germain language and activate The Outpost, TDM will not start anymore (2.13 dev)
-
Then your experience is different than mine. I just recently downloaded a very old mission, The Outpost, that is listed as having German, French, Italian translations, to test out language capabilities. It was not converted (no "#str" found in .map file). Nor was there a language pack included (at least not from thedarkmod downloader).
-
If all written strings were kept in XD files, the process would be easier. We shouldn't need map edits for this. The current system makes mission updates a real problem to the point that only long dormant missions are viable for translation.
-
I don't understand this. When I download a mission, I can still download and update the translation files for it using the build-in mission downloader. Also, the language packs are downloadable for the missions that have them. Nobody is making these language packs though. Not sure why. I heard the translation conversion script is hard to use. I only know 2 languages and there's no need for language packs in one of those (Dutch).
-
BTW, my concern about #str values is about those distributed in FM-specific .lang files. For standard assets, where the info would be in tdm_base01.pk4/all.lang and its derivative .lang files, I guess that's less of a problem. In that case, maybe, instead of using a #str_<number>, you could use a fixed prefix, like: #str_shouldered_<english_name> or #str_moveable_<english_name> That is, like #str_shouldered_chair A general string like that might be used with multiple different chair models, as you intended. If the author overrode the shouldered name with a non-#str name: #str_shouldered_chair --> cushy chair with clue then any translated general strings would be hidden, and just the English version shown.
-
Interesting idea. Not sure about my upcoming time availability to help. A couple of concerns here - - I assume the popup words uses the "Informative Texts" slot, e.g., where you might see "Acquired 80 in Jewels", so it likely wouldn't interfere with that or with already-higher subtitles. - There are indications that #str is becoming unviable in FMs; see my just-posted: https://forums.thedarkmod.com/index.php?/topic/22434-western-language-support-in-2024/
-
In considering my possible upcoming TDM projects, such as upgrading some fonts to Latin-1 or "TDM Latin", I reviewed the current status of support for European Latin-based languages. Basically, for FMs, the translation system has fallen into disrepair and disuse (or perhaps kicked into the grave). Neither "converted" (i.e., #str using) FMs nor Language Packs are now being maintained and distributed by thedarkmod.com. As to other sites, for Cyrillic/Russian, DarkFate provides such resources. Are there any such sites in native Western European tongues, say, German, French, Italian, that likewise offer translated TDM FMs? So, turning back to thedarkmod.com, questions - - is Western Language support (outside the main menu system) officially dead? - if so, maybe it's time to stop pretending otherwise. - if not, should the converted #str system be revived, with better infrastructure? - or an alternative translation system be devised... if so, what? I'm just trying to identify work worth doing. (I started to draft a doc with a litany of problems with Western language support, and possible sub-projects to address them, but TL;DR. And really, not pertinent if support is considered dropped.) Thanks for your thoughts.
-
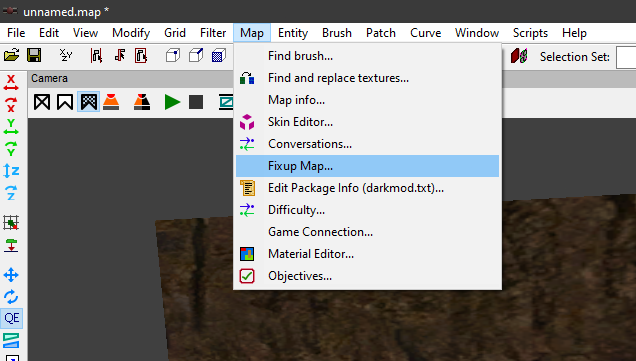
In post https://forums.thedarkmod.com/index.php?/profile/254-orbweaver/&status=3994&type=status @nbohr1more found out what the Fixup Map functionality is for. But what does it actually do? Does it search for def references (to core?) that don't excist anymore and then link them to defs with the same name elswhere? Also I would recommend to change the name into something better understood what it is for. Fixup map could mean anything. And it should be documented in the wiki.
-
Right now it cannot be done (the way I think you picture it) but mission details could be made available by the developers for modding ... In the meantime: Use AngelLoader (the one tool for all your mission management needs) Use the Unofficial Patch (or parts of) Raise your voice here Set the language to Italian (ah!) Build your own executable
-
 Yes. Sure, I will change it, but I do mind. In addition to changing the forum title, I have also had the name of the pk4 changed in the mission downloader and the thiefguild.com site’s named changed. It's not just some "joke". The forum post and thread are intended to be a natural extension of the mission’s story, a concept that is already SUPER derivative of almost any haunted media story or most vaguely creepy things written on the internet in the past 10 or 15 years. Given your familiarity with myhouse.wad, you also can clearly engage with something like that on some conceptual level. Just not here on our forums? We can host several unhinged racist tirades in the off-topic section but can’t handle creepypasta without including an advisory the monsters aren’t actually under the bed? (Are they though?) I am also trying to keep an open mind, but I am not really feeling your implication that using a missing person as a framing of a work of fiction is somehow disrespectful to people who are actually gone. I have no idea as even a mediocre creative person what to say to that or why I need to be responsible for making sure nobody potentially believes some creative work I am involved in, or how that is even achievable in the first place. Anyway, apologies for the bummer. That part wasn’t intentional. I am still here. I will also clarify that while I love the game, I never got the biggest house in animal crossing either. In the end Tom Nook took even my last shiny coin.
Yes. Sure, I will change it, but I do mind. In addition to changing the forum title, I have also had the name of the pk4 changed in the mission downloader and the thiefguild.com site’s named changed. It's not just some "joke". The forum post and thread are intended to be a natural extension of the mission’s story, a concept that is already SUPER derivative of almost any haunted media story or most vaguely creepy things written on the internet in the past 10 or 15 years. Given your familiarity with myhouse.wad, you also can clearly engage with something like that on some conceptual level. Just not here on our forums? We can host several unhinged racist tirades in the off-topic section but can’t handle creepypasta without including an advisory the monsters aren’t actually under the bed? (Are they though?) I am also trying to keep an open mind, but I am not really feeling your implication that using a missing person as a framing of a work of fiction is somehow disrespectful to people who are actually gone. I have no idea as even a mediocre creative person what to say to that or why I need to be responsible for making sure nobody potentially believes some creative work I am involved in, or how that is even achievable in the first place. Anyway, apologies for the bummer. That part wasn’t intentional. I am still here. I will also clarify that while I love the game, I never got the biggest house in animal crossing either. In the end Tom Nook took even my last shiny coin. -
I've seen fun workarounds like that in other game modding as well. Years ago, maybe even a decade, some fella who was making a mod for Mount & Blade over at the Taleworlds forums revealed that he put invisible human NPCs on the backs of regular horse NPCs, then put the horse NPCs inside a horse corral he built for one of his mod's locations/scenes and then did some minor scripting, so the horses with invisible riders would wander around the corral. The end result was that it looked they're doing this of their own will, rather than an NPC rider being scripted to ride around the corral slowly. Necessity is the mother of invention. I don't know about the newest Mount & Blade game, but the first generation ones (2008-2022) apparently had some sort of hardcoded issue back in the earlier years, where if you left a horse NPC without a rider in its saddle, the horses would just stand around and wait and you couldn't get them to move around. Placing an invisible rider in their saddles suddenly made it viable again, at least for background scenes, of riderless horses wandering around, for added atmosphere. First generation M&B presumed you'd mostly be seeing horses in movement with riders, and the only horses-wandering-loosely animations and scripting were done for situations when the rider was knocked off their horse or dismounted in the middle of a battle. Hence the really odd workarounds. So, an invisible NPC trick might not be out of the question in TDM, even though you could probably still bump into it, despite its invisibility.
-
DarkRadiant 3.9.0 is ready for download. What's new: Feature: Add "Show definition" button for the "inherit" spawnarg Improvement: Preserve patch tesselation fixed subdivisions when creating caps Improvement: Add Filters for Location Entities and Player Start Improvement: Support saving entity key/value pairs containing double quotes Improvement: Allow a way to easily see all properties of attached entities Fixed: "Show definition" doesn't work for inherited properties Fixed: Incorrect mouse movement in 3D / 2D views on Plasma Wayland Fixed: Objective Description flumoxed by double-quotes Fixed: Spinboxes in Background Image panel don't work correctly Fixed: Skins defined on modelDefs are ignored Fixed: Crash on activating lighting mode in the Model Chooser Fixed: Can't undo deletion of atdm_conversation_info entity via conversation editor Fixed: 2D views revert to original ortho layout each time running DR. Fixed: WX assertion failure when docking windows on top of the Properties panel on Linux Fixed: Empty rotation when cloning an entity using editor_rotatable and an angle key Fixed: Three-way merge produces duplicate primitives when a func_static is moved Fixed: Renderer crash during three-way map merge Internal: Replace libxml2 with pugixml Internal: Update wxWidgets to 3.2.4 Windows and Mac Downloads are available on Github: https://github.com/codereader/DarkRadiant/releases/tag/3.9.0 and of course linked from the website https://www.darkradiant.net Thanks to all the awesome people who keep creating Fan Missions! Please report any bugs or feature requests here in these forums, following these guidelines: Bugs (including steps for reproduction) can go directly on the tracker. When unsure about a bug/issue, feel free to ask. If you run into a crash, please record a crashdump: Crashdump Instructions Feature requests should be suggested (and possibly discussed) here in these forums before they may be added to the tracker. The list of changes can be found on the our bugtracker changelog. Keep on mapping!
- 2 replies
-
- 15
-

-

-
TDM 15th Anniversary Contest is now active! Please declare your participation: https://forums.thedarkmod.com/index.php?/topic/22413-the-dark-mod-15th-anniversary-contest-entry-thread/
-
-
1
-
- Report
-
Ah, pity I wasn't reading the forums back in February. I'm fond of that game, along with Bugbear's other early title, Rally Trophy. I was never too good at FlatOut, but it was always a hoot to play.
-

The Dark Mod 15th Anniversary Contest ? ( POLL ADDED )
nbohr1more replied to nbohr1more's topic in Fan Missions
Language is a tough game. The "lack of a theme" is still a "Contest Theme" when compared to other Contests that have defined themes depending on how deep you want to into a taxonomy discussion. I would have preferred that free-for-all was off the menu but there is a demand for that option. -
@snatcher I understand that when you feel your work doesn't live up to your goals that you don't want it out in the wild advertising your own perceived shortcomings but that leads to a troubling dilemma of authors who are never satisfied with their work offering fleeting access to their in-progress designs then rescinding them or allowing them to be lost. When I was a member of Doom3world forums, I would often see members do interesting experiments and sometimes that work would languish until someone new would examine it and pickup the torch. This seemed like a perfectly viable system until Doom3world was killed by spambots and countless projects and conceptual works were lost. I guess what I am trying to say is that mods don't need to be perfect to be valuable. If they contain some grain of a useable feature they might be adapted by mission authors in custom scenarios. They might offer instructive details that others trying to achieve the same results can examine. It would be great if known compelling works were kept somewhere safe other than via forum attachments and temporary file sharing sites. I suppose we used to collect such things in our internal SVN for safe keeping but even that isn't always viable. If folks would rather not post beta or incomplete mods to TDM's Moddb page, perhaps they would consider creating their own Moddb page or allow them to be added to my page for safe keeping. Please don't look at this as some sort of pressure campaign or anything. I fully understand anyone not willing to put their name next to something they aren't fully happy with. As a general proviso, ( if possible \ permitted ) I just want to prevent the loss of some valuable investigations and formative works. The end of Doom3world was a digital apocalypse similar to the death of photobucket. It is one of my greatest fears that TDM will become a digital memory with only the skeletons of old forum threads at the wayback archive site.
-
Congrats on the release! Remember to check ThiefGuild as well as the DarkFate forums (via Google Translate) for additional feedback.
-
Changelog of 2.13 development: beta213-05 (rev 17312-10946) * Removed back menuLastGameFrame feature because of random texture popup (post). * Console font minor tweak to avoid artifact under P. * Minor fix for Catalan language. beta213-04 (rev 17306-10940) * Fixed bug with compass + X-ray glasses combination. * Fixed two buttons displayed in menu objectives during game (post). * Added new smoking animation. * Added menuLastGameFrame image to show game footage in in-game main menu (6608). * Changed install/uninstall mission to select/deselect in main menu. * Fixed editor images for HD carpets (6607). * More fixes for Catalan language. beta213-03 (rev 17294-10935) * Fixed crash in WS3 due to script name collision in invisibility potion. * Added praying animation. * Fixed heat-haze shaders with nontrivial Render Scale. * Restored back tonemapping in the menus. * Allow settings hotkeys for gasmine, slowfall, invisibility, made strings translatable. * Fixed double-cursor in game console on 1920x1080 (post). * Applied noise reduction to new vocals for drunk "jack" AI. * Added support for Catalan language. * Fixed UV maps on stove models (6312). beta213-02 (rev 17281-10932) * Fixed HOM-like artifacts in AT1 Lucy and trash frames on TDM start on Linux (post, post). * Disabled tonemap compression curve and reverted settings to 2.12 defaults (post). * Added menu options to disable volumetric lights and parallax mapping. * Fixed varioius issues with largesquare01 materials (6579). * Fixed several issues in the new parallax materials (6604). * Deleted plain_redgreen_design_HD material which references non-existent textures (6601). * Some main menu buttons during game start replaced with generic "Next" (post). * Climbing sounds now depend on material (4991). * Added shaded_lamp_with_grill model (6589). * New fabric_ornate and fabric_fleur materials. beta213-01 (rev 17262-10927) * Improving the fonts continued (thread). * Fixed unwanted mine deployment when player eats the last bit of food in hands (6598). * Removed old hack to fix for scripted savegame crash (4967). * Added a model ext_timber01_window01_empty.lwo (6600). * Fixed missing skin for atdm:ai_revenant_spirit (6595). dev17251-10920 * Added slowfall potion. * Added invisibility potion. * New tonemap settings are now default (post). * Added Texture Quality settings in the main menu. * Added pipes_industrial_modular models. * Minor adjustments to colored versions of gen3 environment maps. * Default value of inv_count is back at 1 to fix issues with inventory counts. * Fixed rare crash on loading collision models (post). * Refactored heatHaze shaders. dev17234-10914 * Added many new high-res materials, half of them with parallax mapping. * Implemented optional HDR compression in tonemapping + other improvements (post). * Implemented interactionSeparator syntax in materials (post). * Added new entityDef: atdm:radio. * Added colored versions of gen3 environment cubemaps for metallic materials. * Added new environment cubemaps: sparkles, studio, blurry. * Added coat_commoner_hanging and coat_inventor_hanging models. * Added mantle_clock_ticking sound. * Improved lightgem calculations while leaning (post). * Fixed regression with double-sided materials (5862). * New sorting of inventory grid items (6592). * Reduced font size of mission list, which allows to see more missions and longer names (post). * Added scrollbar to "notes" of a mission in the main menu. * Optimization: don't render interaction groups with black diffuse & specular. * Improved "scepter" material (thread). * Fixed normal map of ornament_relief_mold_eaglelshield (6585). * More tweaks to starry2 materials. * Made material noshadows: moon_full_shaded, shooting_star, moon_glow. * Added "inv_count" "1" spawnarg to atdm:playertool. * Gas mine now costs 125 instead of 75. * Added min/max builtin functions to game scripts. * Added script events about gravity, health, in-air movement. * Added script events setUserBy, setFrobActionScript. dev17171-10894 * Added entityDef archery_target01 with hit detection, it is now used in Training Mission. * Fixed missing steam_pipe02_straight in Training Mission. * Hiding mouse cursor during briefing in official missions (6576). * Cleaned up the code for extracting interaction groups in material. * Parallax mapping: supported "translate", self-shadows are disabled properly (6571). * Fixed meshes generator_big, generator_small, generator2, warehouse_front_doorframe (6581). * Fixed material on model stove_open02 (6580). * Fixed decals on ext_timber01_window01 (5782). * Improved largesquare01 materials with bumpmap and specular (6579). * Added skybox materials clouds3 and clouds_4_small + prefabs. dev17152-10890 * Major update of Training Mission, including vine arrows (4352). * Added TDM version + engine revision in lower-left corner of main menu. * Experimental implementation of parallax mapping (6571). * Fixed frob interaction with candle holder that's initially extinguished (6577). * Better icons for scrollbar thumb in menu, fixed author search (6339 6570 6449). * Fixed hiding mouse cursor during video briefing/debriefing (6576). * Fixed map immobilization not applied if opening map with inv use key. * Forbid adding missions to download when download is in progress (6368). * Skip disabled bump stages in environment mapping (6572). * Disabled texture compression for light images: falloff and IBL cubemaps. * Minor change in shadow map acne / blur radius computation (6571). * Added banner01_edgar and banner01_viktor banners, along with long versions. * Fixed UV map for longbanner_ragged model (6573). * Added missing jack/drunk_idle13.ogg sample (6507). * Fixed handle_curved02_latch prefab, deleted pull_handle (6286). * Replaced normal map of cobblestone_blue_black with high-res version (6574). * More detailed editor images of some materials (6575). * Added small_dresser_openable prefab. * Added banner_sword + tdm_bannerlong_sword materials. * Increased size of secret message overlay GUI. dev17121-10869 * Massive improvements in mission select & download menus, added search (6339 6570 6449). * Improvements and fixes for "builder priest" animated mesh. * Improvements of idle01 animation. * Improved newspaper01 model (6568). * Added gas mine to "map start pack" prefabs (6559). * Fixed text alignment in save/load menus. * Minor CI/build fixes. dev17104-10844 * Enabled the new system for tracking light value by default (6546). * New light value tracking integration covers ropes and doors + optimized shadow rays (6546). * Added atdm:playertools_gasmine (6559). * Workaround for compiler bug which broke particle collisions with texture layout (post). * Fixed r_showTris: color, values 2 and 3 (6560). * Minor improvements to drunk vocals (6507). * More tweaks to sculpted/girard_relief_pho. dev17095-10833 * Major improvements in drunk AIs: setting "drunk" spawnarg is enough now; new sounds, animation improvements, greetings, etc. (6507). Fixed drunk women AI (5047). * Incorporated stone font updates by Geep (thread). * New footstep sounds for ice and broken glass (6551). * Fixed light culling bug on elongated models with non-identity rotation (6557). * Added new system for tracking light value of entities (6546). It is disabled yet. * Technical change in loading of particle collisions (6546). * Now AI follower settings can be set as spawnargs, added prefab (6552). * Added proper dmap error message if map file contains an entity before worldspawn. * Fixed water_medium_running sound (5384). * Fixed window/metal_irregularpanes_moonlit material. * Fixed wood/boards/rough_boards_scratched (4157). * Fixed wall/ship_wheel model (6549). * Fixed gaps in awning_cloth_01_large model (6550). * Added weather particles with static collisions enabled (6545). * Added a pack of new factory_machines models (6537). * Added fabric/cloth_baize materials (red and purple). * Added window/diamond_pattern01_moonlit_bright material (6133). * Added AO and specular maps to sculpted/girard_relief material. * Added musicbox sound, added prefabs for it and for victrola. * Added wood/panels/mary_panel model. * DarkRadiant now knows about parallelSky param (6496). dev17056-10800 * Supported "efx_preset" spawnarg on location entities (6273, thread). * Fixed rendering of volumetric light and particles in X-ray views (6538). * Fixed rendering of particles in mirrors (6538). * Improved volume estimation for subtitles, very quiet subtitles are hidden (6491). * Fixed bug in idClip::Translation of non-centered models. * Third-party integration greatly reworked for better integration with conan (6253). * Stone/subtitle font improvements by Geep. * Fixed sleeping sounds for drunk AIs (6539), and other sounds for them too (6507). * Fixed missing shadow on endtable_001 model (6288). * Added girard_relief material. Known issues: * Shadows of Northdale Act 1 does not start (6509). (mission has been updated) dev17044-10746 * Supported mission overrides for cvars which are tied to gameplay state (5453). * Fixed crash on start with 32-bit Windows build. * Rebuilt all third-party libraries with conan 2 system (6253). * Reverted improvements of capped FPS to fix video/audio desync (5575). dev17042-10732 * Restored ability to create cvars dynamically, fixing bow in missions (5600). * Fixed issue where .cfg files were saved every frame (5600). * Added sys.getcvarf script event for getting float value of cvar (6530). * Extracted most of constants from weapon scripts into cvars (6530). dev17035-10724 * Support passing information between game and briefing/debriefing GUI via persistent info. Also changed start map & location selection, added on_mission_complete script callback (6509 thread). * New bumpmapped environment mapping is now default (6354). * New behavior of zero sound spawnarg is now default (6346). * Added sound for "charge post" model (6527). * Major refactoring of cvars system to simplify future changes (5600). Known issues: * Bow does not shoot in some missions: thread (only in this dev build) dev17026-10712 * Nested subviews (mirrors, remotes, sky, etc.) now work properly (6434). * Added GUI debriefing state on mission success (6509 thread). * Sound argument override with zero now works properly under cvar (6346 thread). * Environment mapping is same on bumpy and non-bumpy surfaces under cvar (6354 thread). * Default console font size reduced to 5, added lower bound depending on resolution. * Added high-quality versions of panel_carved_rectangles (6515). * Added proper normal map for stainglass_saint_03 (6521). * Fixed DestroyDelay warning when closing objectives. * Fixed the only remaining non-threadsafe cvar (5600). * Minor optimization of depth shader. * Added cm_allocator debug cvar (6505). * Fixed r_lockView when compass is enabled. dev17008-10685 * Enabled shadow features specific to maps implementation (poll). * Auto-detect number of parallel threads to use in jobs system (6503). * Improved parallel images loading, parallelized sounds loading, optimized EAS (6503). * Major improvements in mission loading progress bar (6503). * Core missions are now stored uncompressed in assets SVN (6498). * Deleted a lot of old rendering code under useNewRenderPasses + some cleanup (6271). dev16996-10665 * Environment mapping supports texcoord transforms on bumpmap (6500). * Fully disabled shadows on translucent objects (6490). * Fixed dmap making almost axis-aligned visportals buggy (6480). * com_maxFps no longer quantizes by milliseconds on Windows 8+. * Now Uncapped FPS and Vsync are ON by default. * Supported Vsync control on Linux. * Added set of prototype materials (thread). * Fixes to Stone font to remove stray pixels (post). * Loot candlestick no longer toggle the candle when taken. * Optimized volumetric lights and shadows in the new Training Mission (4352). * Fixed frob_light_holder_toggle_light on entities with both skin_lit and skin_unlit. * Now combination lock supports non-door entities by activating them. * Added low-poly version of hedge model (6481). * Added tiling version of distant_cityscape_01 texture (6487). * Added missing editor image for geometric02_red_end_HD (6492). * Added building_facades/city_district decal material. * Fixed rendering with "r_useScissor 0" (6349). * Added r_lockView debug rendering cvar (thread). * Fixed regression in polygon trace model (5887). * Added a set of lampion light entityDefs.
-
Help Wanted: Beta Testers -- "The Terrible Old Man"
nbohr1more replied to Ansome's topic in Fan Missions
Welcome to the forums Ansome! And congrats on making it to beta phase! -
"...to a robber whose soul is in his profession, there is a lure about a very old and feeble man who pays for his few necessities with Spanish gold." Good day, TDM community! I'm Ansome, a long-time forums lurker, and I'm here to recruit beta testers for my first FM: "The Terrible Old Man", based on H.P. Lovecraft's short story of the same name. This is a short (30-45 minute), story-driven FM with plenty of readables and a gloomy atmosphere. Do keep in mind that this is a more linear FM than you may be used to as it was deemed necessary for the purposes of the story's pacing. Regardless, the player does still have a degree of freedom in tackling challenges in the latter half of the FM. If this sounds interesting to you, please head over to the beta testing thread I will be posting shortly. Thank you!


- 6 replies
-
- 10
-
-
Is this really a problem? Maybe we can figure that out before reverting the "J", which previously was so badly spaced it looked like it had a space character after it. It would be helpful to identify which missions have such pseudographics. I suspect it's a small number. And those using Stone font smaller still. In that regard, I did some preliminary experiments, limited to a cohort of 46 FMs on my machine with expanded FM .pk4s, that I can do full-text searches across files on, with TextPad. (@stgatilov, I imagine you are in a position to similarly and more conclusively search the entire english FM collection.) I searched with characters (or short strings) that would be likely to be found in pseudographics. For untranslated FMs, I searched in filenames of form *.xd . For translated FMs (those that had string "#str_" in their *.xd; there were 8 such FMs in my cohort) I searched in file english.lang Results Many search strings were useless due to too many false hits: "_" Widely used as part of internal xd name. Used on separate line as heading underscore. "/" Widely used as part of internal xd name. "\" (except "\\") Widely used \n or \" escape character "--" (assuming single dash is everywhere) Several in a row to bracket a heading, or as part of a letter's signature. Used on separate line, as heading underscore or as border between paragraphs These search strings were moderately useful, showing up in just a few FMs (tho none were pseudographics on examination): "=" Used on separate line as heading underscore (in penny3's erasing.xd) "+" Used as bullet points, or (several in a row) to bracket a heading (in penny3's erasing.xd; in bcd's english.lang) These search strings were most promising: "|" Only 1 hit, but it's a table-form pseudographic! (northdale1's snowedinn.xd) "\\" (i.e., escaped \) No hits found in my cohort Inspection of snowedinn.xd showed this: Note that it uses book_calig_mac_humaine.gui; so this pseudographic was not in Stone font
-
New script for mappers: my flavour of a fog density fading script. To add this to your FM, add the line "thread FogIntensityLoop();" to your map's void main() function (see the example in fogfade.script) and set "fog_fade" "1" on each foglight to enable script control of it. Set "fog_intensity_multiplier" on each info_location entity to change how thick the fog is in that location (practically speaking it's a multiplier for visibility distance). Lastly, "fog_fade_speed" on each foglight determines how quickly it will change its density. The speed scales with the current value of shaderParm3, using shaderParm3 = 1000 as a baseline. So i.e. if shaderParm is currently at 1/10th of 1000, then fade speed will be 1/10th as fast. Differences to Obsttorte's script: https://forums.thedarkmod.com/index.php?/topic/14394-apples-and-peaches-obsttortes-mapping-and-scripting-thread/&do=findComment&comment=310436 my script uses fog lights you created, rather than creating one for you. Obsttorte's script will delete the foglight if entering a fogfree zone and recreate it later more than one fog light can be controlled (however, no per-fog-light level of control) adding this to the map requires adding a line to your void main() script, rather than adding an info_locations_settings entity with a custom scriptobject spawnarg in my script, mappers set a multiplier of fog visibility distance (shaderParm3), while in Obsttorte's script a "fog_density" spawnarg is used as an alternative to shaderParm3 smaller and less compactly written script fogfade.scriptfogfade.map
-
Ah, you're right, it can be more language-specific or even project-specific. We often used setters that returned this, so we could use method chaining, but this isn't a general rule.












