Search the Community
Showing results for '/tags/forums/learning mapping/'.
-
 Because it's super useful not having to browse through the whole thread, and probably not even finding what you're looking for, because people put it in spoiler tags, which are excluded from the search. You don't have to click on the spoiler tag in the original post.
Because it's super useful not having to browse through the whole thread, and probably not even finding what you're looking for, because people put it in spoiler tags, which are excluded from the search. You don't have to click on the spoiler tag in the original post. -
 Basically someone always asks. We're all grownups here and it's in spoiler tags so...
Basically someone always asks. We're all grownups here and it's in spoiler tags so... -
Isn't that just if you have a moveable or something behind a wall and its frob_distance is greater than the thickness of the wall? Walls don't block frobbing unfortunately, which is why you get those mapping bugs where you can frob paintings through the wall.
-
I hope that is not the new TDM version. https://forums.thedarkmod.com/index.php?/topic/20784-render-bug-large-black-box-occluding-screen/
-
For free ambience tracks it's as Freky said: you look around on the internet for tracks with the appropriate license to be included in your FM. Fortunately, you likely don't even need to bother doing this as a beginner as there's an entire "Music & SFX" section of the forums full of good ambient tracks for you to use if the stock tracks do not meet your fancy. You might also be interested in Orbweaver's "Dark Ambients", which come with a sndshd file already written for you.
-
Beta Testers Wanted. The Lieutenant 3: Foreign Affairs
Frost_Salamander replied to Frost_Salamander's topic in Fan Missions
For the FM? For beta 1 it's here: https://drive.proton.me/urls/H1QBB04GA0#oBZTb1CmVFQb I've already done around 100 fixes though, so you might want to wait for beta 2 which should be ready in a couple of days hopefully. All links are in the first post of the beta thread here: https://forums.thedarkmod.com/index.php?/topic/22439-the-lieutenant-3-foreign-affairs-beta-testing/ -
Also, I've built another console app, "datBounds", to visualize the bounding box around each bitmap character. Starting from your choice of .dat, .fnt, or .ref file, it generates a set of .tga files, e.g., stone_0_24_bounds.tga & stone_1_24_bounds.tga. You can optionally include a 2-hex-digit label on each bounding box. More about that in May. I'm using the results of this to understand the current complex codepoint mapping of the Stone 24pt glyphs, and develop the workplan and grid layouts for upcoming work.
-
Interesting idea. Not sure about my upcoming time availability to help. A couple of concerns here - - I assume the popup words uses the "Informative Texts" slot, e.g., where you might see "Acquired 80 in Jewels", so it likely wouldn't interfere with that or with already-higher subtitles. - There are indications that #str is becoming unviable in FMs; see my just-posted: https://forums.thedarkmod.com/index.php?/topic/22434-western-language-support-in-2024/
-
In post https://forums.thedarkmod.com/index.php?/profile/254-orbweaver/&status=3994&type=status @nbohr1more found out what the Fixup Map functionality is for. But what does it actually do? Does it search for def references (to core?) that don't excist anymore and then link them to defs with the same name elswhere? Also I would recommend to change the name into something better understood what it is for. Fixup map could mean anything. And it should be documented in the wiki.
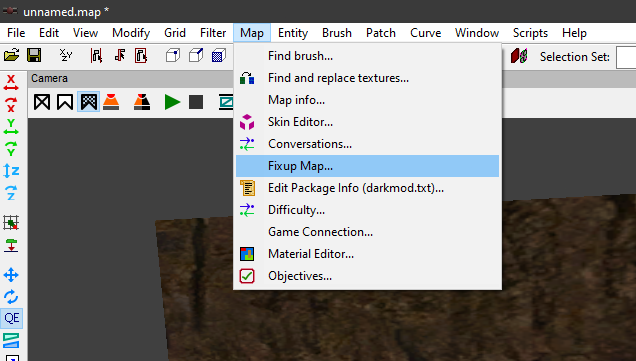
-
This last month, I've been exploring TDM's font situation, and improving the documentation as I go. In the wiki, "Font Conversion & Repair" was rewritten, with parts broken out and expanded as: Font Files Font Metrics & DAT File Format Font Bitmaps in DDS Files ExportFontToDoom3 Q3Font Refont As announced earlier, that last item is a new C++ console utility for revising font metrics in DAT files; essentially another alternative to Q3Font and Font Patcher. It now has additional functionality that provides font-coverage analysis. A summary of current results across all TDM fonts is reported in the forum thread "Analysis of 2.12 TDM Fonts". Also, refont allows its human-readable outputs to be decorated with an annotation for each character (out of 256 codepoints). Associated with that, I've just created and released 4 annotation files: 1 Cyrillic version for TDM's russian map 3 variants for TDM's custom english/european char map. One of the variants was derived from another new mapping file that is now available from existing wiki article "I18N - Charset". Within that file is a list, in a standard format, of the 256 TDM bitmap codepoints mapped to the corresponding Unicode U+NNNN value and name. This may be useful in defining TDM's mapping to TTF font editing programs. For all these wiki pages mentioned, I imagine there will be additional cross-links and tweaks. But pretty much done.
-

Should we consider using detail textures?
The Black Arrow replied to MirceaKitsune's topic in The Dark Mod
Alright, so, I'm a Texture Artist myself for more than 20 years, which means I know what I'm talking about, but my word isn't law at all, remember that. I've worked (mostly as mods, I am a professional but I much prefer being a freelance) with old DX8 games up to DX12. When it comes to Detail Textures, for my workflow, I never ever use it except rarely when it's actually good (which, I emphasize on "rarely"). This is one reason I thought mentioning that I worked with DX8 was logical. One of the few times it's good is when you make a game that can't have textures higher than what would be average today, such as, World Textures at 1024x1024. Making detail textures for ANY (World, Model) textures that are lower than 128x128 is generally appealable. Another is when the game has no other, much better options for texturing, such as Normal Maps and Parallax Mapping. Personally, I think having Detail Textures for The Dark Mod is arguably pointless. I know TDM never had a model and texture update since 2010 or so, but most textures do seem to at least be 1024x1024, if there's any world texture that's lower than 256x256, I might understand the need of Detail Textures. Now, if this was a game meant to be made in 2024 with 2020+ standards, I would say that we should not care about the "strain" high resolution textures add, however, I do have a better proposition: Mipmaps. There are many games, mostly old than new ones, that use mipmaps not just for its general purpose but also to act as a "downscaler". With that in mind, you boys can add a "Texture Resolution" option that goes from Low to High, or even Lowest to Highest. As an example, we can add a 2048x2048 (or even 4096x4096) world texture that, if set to Lowest, it would use the smallest Mipmap the texture was made with, which depends on how the artist did it, could be a multiplication of 1x1 or 4x4. One problem with this is that, while it will help in the game with people who have less VRAM than usual these days, it won't help with the size. 4096x4096 is 4096x4096, that's about 32mb compressed with DXT1 (which is not something TDM can use, DXT is for DirectX, sadly I do not know how OpenGL compresses its textures). I would much rather prefer the option to have better, baked Normal Maps as well as Parallax Mapping for the World Textures. I'm still okay with Detail Textures, I doubt this will add anything negative to the game or engine, very sure the code will also be simple enough it will probably only add 0.001ms for the loading times, or even none at all. But I would also like it as an option, just like how Half-Life has it, so I'm glad you mentioned that. But yet again, I much prefer better Normal Maps and Parallax Mapping than any Detail Textures. On another note...Wasn't Doom 3, also, one of the first games that started using Baked Normal Maps? -

Can DR be used with engines like Godot?
datiswous replied to Skaruts's topic in DarkRadiant Feedback and Development
Could you store that somewhere? For example in Github. I'm learning Godot at the moment and might be interested in this in the future. -
Turns out my 15th anniversary mission idea has already been done once or twice before! I've been beaten to the punch once again, but I suppose that's to be expected when there's over 170 FMs out there, eh? I'm not complaining though, I love learning new tricks and taking inspiration from past FMs. Best of luck on your own fan missions!
-
-
 1
1
-
- Report
- Show previous comments 1 more
-
Damn, 7 Sisters, wasn't that one made by the late Lady Rowena? I have to play it, I remember playing it right after she died and I didn't even notice, those news disturbed me enough not to play 7 Sisters for the time being.
Very sad that she died, she made one of the very best FMs out there. My very first FM was one of hers even, Lady Rowena's Curse.
-
-
1
-
- Report
-

Yeah I still remember her too and the Seven Sisters FM...
-

Now I remember what the other FM was. I wanted to have part of mine set in a hospital, and T2X, which came out right afterwards too, had a level set in a hospital. After that experience I thought for most ideas you have, someone is going to have thought along similar lines. But the thing is people can have their own takes with the same idea too. So I think it's okay to have the same idea played out, if you give it your own spin.
-
-
1
-
- Report
-
 Yes. Sure, I will change it, but I do mind. In addition to changing the forum title, I have also had the name of the pk4 changed in the mission downloader and the thiefguild.com site’s named changed. It's not just some "joke". The forum post and thread are intended to be a natural extension of the mission’s story, a concept that is already SUPER derivative of almost any haunted media story or most vaguely creepy things written on the internet in the past 10 or 15 years. Given your familiarity with myhouse.wad, you also can clearly engage with something like that on some conceptual level. Just not here on our forums? We can host several unhinged racist tirades in the off-topic section but can’t handle creepypasta without including an advisory the monsters aren’t actually under the bed? (Are they though?) I am also trying to keep an open mind, but I am not really feeling your implication that using a missing person as a framing of a work of fiction is somehow disrespectful to people who are actually gone. I have no idea as even a mediocre creative person what to say to that or why I need to be responsible for making sure nobody potentially believes some creative work I am involved in, or how that is even achievable in the first place. Anyway, apologies for the bummer. That part wasn’t intentional. I am still here. I will also clarify that while I love the game, I never got the biggest house in animal crossing either. In the end Tom Nook took even my last shiny coin.
Yes. Sure, I will change it, but I do mind. In addition to changing the forum title, I have also had the name of the pk4 changed in the mission downloader and the thiefguild.com site’s named changed. It's not just some "joke". The forum post and thread are intended to be a natural extension of the mission’s story, a concept that is already SUPER derivative of almost any haunted media story or most vaguely creepy things written on the internet in the past 10 or 15 years. Given your familiarity with myhouse.wad, you also can clearly engage with something like that on some conceptual level. Just not here on our forums? We can host several unhinged racist tirades in the off-topic section but can’t handle creepypasta without including an advisory the monsters aren’t actually under the bed? (Are they though?) I am also trying to keep an open mind, but I am not really feeling your implication that using a missing person as a framing of a work of fiction is somehow disrespectful to people who are actually gone. I have no idea as even a mediocre creative person what to say to that or why I need to be responsible for making sure nobody potentially believes some creative work I am involved in, or how that is even achievable in the first place. Anyway, apologies for the bummer. That part wasn’t intentional. I am still here. I will also clarify that while I love the game, I never got the biggest house in animal crossing either. In the end Tom Nook took even my last shiny coin. -
I've seen fun workarounds like that in other game modding as well. Years ago, maybe even a decade, some fella who was making a mod for Mount & Blade over at the Taleworlds forums revealed that he put invisible human NPCs on the backs of regular horse NPCs, then put the horse NPCs inside a horse corral he built for one of his mod's locations/scenes and then did some minor scripting, so the horses with invisible riders would wander around the corral. The end result was that it looked they're doing this of their own will, rather than an NPC rider being scripted to ride around the corral slowly. Necessity is the mother of invention. I don't know about the newest Mount & Blade game, but the first generation ones (2008-2022) apparently had some sort of hardcoded issue back in the earlier years, where if you left a horse NPC without a rider in its saddle, the horses would just stand around and wait and you couldn't get them to move around. Placing an invisible rider in their saddles suddenly made it viable again, at least for background scenes, of riderless horses wandering around, for added atmosphere. First generation M&B presumed you'd mostly be seeing horses in movement with riders, and the only horses-wandering-loosely animations and scripting were done for situations when the rider was knocked off their horse or dismounted in the middle of a battle. Hence the really odd workarounds. So, an invisible NPC trick might not be out of the question in TDM, even though you could probably still bump into it, despite its invisibility.
-
I plan to gradually try out all or most of the different path node types and adjust them depending on the interaction. Though I don't plan to use it in this particular mission, I have a keen interest in the follow type, as I'll want an NPC to follow the player character in another, future FM I'd like to create. Never too soon to try out various functions while I'm already learning new FM-building skins after a long hiatus. Thank you for the suggestion. I completely forgot about the location system ambients as an option ! A few years back, when I was testing various stuff in DR, I did actually use that approach instead, once or twice. I haven't used DR much in recent years, so I eventually forgot about setting it up that way. Acknowledged, and I'll look into it. It'll save a lot of time concerning the audio side of the mission. My first few missions won't have much a natural environment, they'll largelly be small and focused on buildings or urban spaces, so I won't need to bother with detailed audio for rivers yet. I have an outdoor FM planned for later (it's in the pre-production phase), and I'll have a good reason to study it in greater detail. It's actually okay, I don't reallt need rectangular speakers. Given that I've been reminded I can set a main ambience for each room - something I did know before, but forgot, after not working properly with DR these past few years - I'll do just that, and use the speakers for more secondary ambience concerns. Handy indeed. A rectangular shape would be easier to remember. I'll just use the filters in the editor to put away the speakers if I ever the get the impression they're blocking my view. Also, I don't actually mind the shape all that much. As you and the others say, the size/radius of the speaker is the actual key aspect. I'm a bit disappointed it's seemingly not possible to resize speakers the same way you can resize brushes or certain models, though you can still tweak the radius numerically, manually. As long as I can work with that, the actual shape of a speaker isn't really important. My main concern is expanding the minimum and maximum radius areas to an extent where they'll be audible for most for all of the respective areas the player will visit, rather than fading away quickly once the player leaves the hub of the speaker behind. As was already said above, I'll use the different utility to set the main ambient for the individual rooms, rather than a manually placed speaker, and I'll reserve the speakers for additional sound effects or more local ambience. I've already added some extra parameters to the speakers I'm testing out in my FM, so I'll take a look at those soon, though I'll deal with the main room ambience settings first. I'd like to thank everyone for their replies. While I'm not surprised by the answers, I'm now more confident in working with the path node and speaker entities. On an unrelated sidenote to all of this, the same in-development FM where I'm testing the speaker placement and range was tested yesterday for whether an NPC AI can walk from the ground floor all the way to the topmost floor, without issues. Thankfully, there have been no issues at all, and the test subject - a female mage, whom I won't use in the completed FM, sadly - did a successful first ascent of the tower-like building that'll serve as the main setting. (That's all your getting from me for now, concerning the FM contents.)
-
DarkRadiant 3.9.0 is ready for download. What's new: Feature: Add "Show definition" button for the "inherit" spawnarg Improvement: Preserve patch tesselation fixed subdivisions when creating caps Improvement: Add Filters for Location Entities and Player Start Improvement: Support saving entity key/value pairs containing double quotes Improvement: Allow a way to easily see all properties of attached entities Fixed: "Show definition" doesn't work for inherited properties Fixed: Incorrect mouse movement in 3D / 2D views on Plasma Wayland Fixed: Objective Description flumoxed by double-quotes Fixed: Spinboxes in Background Image panel don't work correctly Fixed: Skins defined on modelDefs are ignored Fixed: Crash on activating lighting mode in the Model Chooser Fixed: Can't undo deletion of atdm_conversation_info entity via conversation editor Fixed: 2D views revert to original ortho layout each time running DR. Fixed: WX assertion failure when docking windows on top of the Properties panel on Linux Fixed: Empty rotation when cloning an entity using editor_rotatable and an angle key Fixed: Three-way merge produces duplicate primitives when a func_static is moved Fixed: Renderer crash during three-way map merge Internal: Replace libxml2 with pugixml Internal: Update wxWidgets to 3.2.4 Windows and Mac Downloads are available on Github: https://github.com/codereader/DarkRadiant/releases/tag/3.9.0 and of course linked from the website https://www.darkradiant.net Thanks to all the awesome people who keep creating Fan Missions! Please report any bugs or feature requests here in these forums, following these guidelines: Bugs (including steps for reproduction) can go directly on the tracker. When unsure about a bug/issue, feel free to ask. If you run into a crash, please record a crashdump: Crashdump Instructions Feature requests should be suggested (and possibly discussed) here in these forums before they may be added to the tracker. The list of changes can be found on the our bugtracker changelog. Keep on mapping!
- 2 replies
-
- 15
-
-

-
The Dark Mod 15th Anniversary Contest - Entry Thread
datiswous replied to nbohr1more's topic in Fan Missions
If you ever need help with mapping, you can try these tutorials. -

The Dark Mod 15th Anniversary Contest - Entry Thread
thebigh replied to nbohr1more's topic in Fan Missions
Excellent! Happy mapping and I look forward to playing it -
TDM 15th Anniversary Contest is now active! Please declare your participation: https://forums.thedarkmod.com/index.php?/topic/22413-the-dark-mod-15th-anniversary-contest-entry-thread/
-
-
1
-
- Report
-
Ah, pity I wasn't reading the forums back in February. I'm fond of that game, along with Bugbear's other early title, Rally Trophy. I was never too good at FlatOut, but it was always a hoot to play.
-

Allow broadhead arrows to break glass lamps
MirceaKitsune replied to MirceaKitsune's topic in The Dark Mod
Yes, definitely needs to be distinguishable. Clear glass with light bulb visible would be the best way: You know that if you see clear glass and the bulb inside you can shoot it. The distinction isn't always possible to make without first trying it out though... paintings are the best example, you always need to get close to see if a painting can be looted. As for players learning about this, we should add those lights to the tutorial level where the basics of TDM are taught: In one of the hallways we'd have examples with the message "solid lights can't be shot, but ones with fragile glass and a lightbulb can be broken with broadhead arrows", the player is given arrows and can shoot at different lamps to compare. As for explosive barrels those would be cool to have too! In their case they should already be doable with a script, just that no one's ever done them: Remove the barrel, spawn the same explosion as the fire arrow or mine, and some temporary lasting physical debris if possible. Breakable lights would need support added to the builtin spawnfunc. -
I was confused by this as well when I first started learning DR, the user guide is now slightly out of date. Dark Radiant now uses a modular system that you can freely rearrange and add elements to as you see fit. In your screenshot you can see the buttons to add new cameras and orthoviews, which you can move or resize like a browser window. You can do the same with the UI that contains things like the media and entities tab and even drag them out into their own separate UI element if need be. With a little tweaking you should be able to approximate the Doom 3 editor layout by hand. Hope this helps!
-

The Dark Mod 15th Anniversary Contest ? ( POLL ADDED )
jonri replied to nbohr1more's topic in Fan Missions
I've been feeling the itch to start mapping again, and I'd like to pick up my stalled WIP for the next FM building off my first one. If we end up with lighter contest requirements I'd run with this for the fun of participating. If my FM doesn't end up meeting contest criteria I'll still keep the October timeframe as a goal though. A mild requirement like "include a nod to a classic Thief/TDM map somewhere in your mission" sounds like a nice way to keep participation up without going full free-for-all. -
A visually breaking change is planned for 2.13 (6354). Environment mapping is used when material contains a stage like this: { blend add cubeMap env/gen3 texgen reflect } Historically, there are two separate shaders for this case: one if the material has bumpmapping, and one if it does not. Note that if the material has diffuse or specular stage, then bumpmap is added implicitly. The shader with bumpmap was apparently "tweaked" by someone in TDM and got several major differences: it has fresnel term output color is tonemapped to [0..1] range using X / (1 + X) the color multiplier is hardcoded to (0.4, 0.4, 0.4) I'd like to delete all of these differences and restore the same behavior as in non-bumpmapped case. It is also the same behavior which is used in both cases in Doom 3 BFG (and supposedly in Doom 3 too). Speaking of points 1 and 2, nobody will notice the difference except in rare corner cases. The point 3 however is serious. It is also the main reason behind the change. Right now nobody can tweak the intensity of environment mapping: if you try to set red/green/blue/rgb, these settings are simply ignored. Now the problem is that the intensity of most environment mapping materials will change. In core files I see text like this (stainglass_saint_01) : { blend add maskalpha cubeMap env/gen3 // tone down the reflection a bit //I see no evidence that these values do anything red Parm0 * 0.2 green Parm1 * 0.2 blue Parm2 * 0.2 texgen reflect } Since the default parameter was 0.4, after the change this material will get 2x less intensity. The situation is even worse if rgb multiplier is not specified, since then it will change from 0.4 to 1.0, i.e. envmapping will become 2.5 times brighter. I can probably collect the list of all materials using environment mapping, but I'm not sure I'll be able to check them all one by one. Perhaps I can delete existing rgb settings, blindly set "rgb 0.4" and hope for the best.






